SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
This document provides a complete strategic, architectural, technical, and implementation-level explanation of the rag-index.json file.
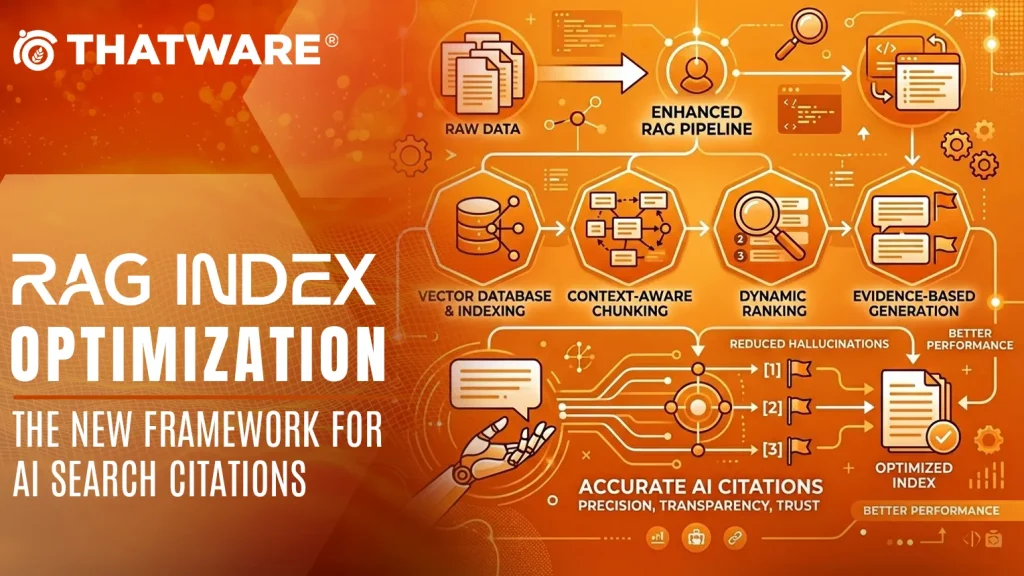
This file is designed for:
· Retrieval-Augmented Generation (RAG)
· Large Language Model optimization
· Generative Engine Optimization (GEO)
· semantic retrieval systems
· vector search systems
· AI citation systems
· semantic chunk orchestration
· contextual answer assembly
· machine-readable retrieval intelligence
This guide explains:
· what rag-index.json is
· why it matters
· how RAG systems work
· how AI retrieval functions
· how retrieval quality impacts LLM answers
· how to optimize retrieval pipelines
· how semantic indexing should be designed
· how chunking systems should operate
· how embeddings influence retrieval
· how AI systems prioritize content
· how retrieval confidence should be modeled
· how enterprise RAG architectures operate
· reusable JSON structures
· production-level implementation patterns
1. What Is rag-index.json?
rag-index.json is a machine-readable retrieval orchestration file that helps AI systems understand:
· what content should be retrieved
· which pages are most important
· which chunks are retrieval-priority assets
· how queries map to content
· which entities connect to which retrieval targets
· how semantic retrieval should behave
· how answer assembly should be guided
· which content is canonical for AI answers
In simple terms:
It is a retrieval intelligence layer for AI systems.

2. What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is an AI architecture that combines:
1. Retrieval Systems
2. Large Language Models
Instead of answering only from pre-trained memory, the AI first retrieves relevant information.
The pipeline usually looks like this:
User Query
→ Query Embedding
→ Vector Search
→ Retrieval Engine
→ Relevant Chunks
→ Context Assembly
→ LLM Answer Generation
RAG improves:
· factual accuracy
· freshness
· contextual relevance
· citation reliability
· hallucination reduction
3. Why rag-index.json Exists
Most websites were never designed for retrieval systems.
Traditional websites optimize for:
· crawling
· indexing
· ranking
· page views
· keyword matching
But RAG systems require:
· semantic chunks
· embedding-friendly content
· retrievable passages
· contextual segmentation
· answer-ready structures
· semantic hierarchy
· retrieval confidence
· canonical answer sources
Without retrieval optimization:
· wrong pages may be retrieved
· irrelevant chunks may dominate
· AI may hallucinate
· citations may be poor
· answers may lack context
· retrieval may become noisy
rag-index.json solves this problem.
4. Core Objective of rag-index.json
The main purpose is to help AI systems answer:
· Which content should be retrieved for Query X?
· Which chunk is most authoritative?
· Which page best explains Topic Y?
· Which retrieval path should be preferred?
· Which semantic cluster should be searched?
· Which chunks should receive priority?
· Which content should be excluded?
· How should context windows be assembled?
5. Why This Matters for GEO
In Generative Engine Optimization, retrieval is one of the most important factors.
AI systems cannot cite or summarize content they fail to retrieve.
rag-index.json improves:
5.1 Retrieval Precision
Better matching between user intent and content.
5.2 Semantic Retrieval
Improves meaning-based retrieval instead of keyword-only retrieval.
5.3 Citation Probability
Retrieval directly affects citation likelihood.
5.4 Context Quality
Improves answer grounding.
5.5 Hallucination Reduction
Better retrieval reduces fabricated answers.
5.6 Canonical Answer Routing
Ensures AI retrieves the best URL.
6. Relationship Between RAG and LLMs
LLMs alone have limitations:
· outdated knowledge
· hallucinations
· context limitations
· weak factual grounding
· missing proprietary information
RAG solves this by dynamically retrieving knowledge.

Modern AI systems increasingly depend on RAG.
Examples:
· ChatGPT retrieval systems
· Perplexity AI
· enterprise AI assistants
· AI copilots
· customer support AI
· semantic enterprise search
· AI research systems
7. How AI Retrieval Works
Typical retrieval pipeline:
1. User asks question
2. Query converted into embeddings
3. Vector database searched
4. Semantic similarity calculated
5. Top chunks selected
6. Context assembled
7. LLM generates answer
Retrieval quality heavily affects final output quality.
8. The Role of rag-index.json in Retrieval
This file helps AI systems understand:
· retrieval priorities
· semantic chunk maps
· query-to-page mapping
· canonical sources
· answer-ready assets
· retrieval confidence
· embedding relationships
· chunk categories
· topical clustering
9. Difference Between Sitemap and RAG Index
XML Sitemap
Answers:
“What URLs exist?”
Semantic Sitemap
Answers:
“What topics do pages belong to?”
rag-index.json
Answers:
“Which semantic chunks should be retrieved for specific intents and questions?”
A sitemap is crawl-focused.
A RAG index is retrieval-focused.
10. Recommended File Location
https://example.com/rag-index.json
Optional:
https://example.com/.well-known/rag-index.json
The file should also be referenced from:
· ai-endpoints.json
· llms.txt
· llmsfull.txt
· knowledge-graph.json
· vector-feed.xml
11. Recommended MIME Type
application/json
12. Core Design Principles
12.1 Retrieval-First Design
Every structure should improve retrieval quality.
12.2 Chunk-Level Intelligence
Optimization should happen at chunk level, not only page level.
12.3 Semantic Query Matching
Queries should match meaning, not just keywords.
12.4 Canonical Retrieval Sources
Every important topic should have preferred retrieval assets.
12.5 Embedding Awareness
Content should be optimized for embedding systems.
12.6 Context Preservation
Chunks should maintain semantic meaning independently.
12.7 Retrieval Confidence
AI systems should understand confidence scores.
13. Main Components of rag-index.json
A strong RAG index should include:
1. metadata
2. retrieval rules
3. query mappings
4. semantic clusters
5. chunk metadata
6. embedding metadata
7. retrieval priorities
8. authority weighting
9. canonical answer sources
10. chunk confidence
11. exclusion rules
12. freshness metadata
13. context assembly rules
14. retrieval thresholds
15. answer-generation hints
16. citation preferences
17. semantic relationships
14. Chunking Fundamentals
Chunking is one of the most important concepts in RAG.
AI systems retrieve chunks, not entire pages.
Poor chunking causes:
· fragmented meaning
· irrelevant retrieval
· weak answers
· hallucinations
· broken context
15. Recommended Chunk Structure
Each chunk should:
· focus on one semantic idea
· contain contextual continuity
· include entity references
· avoid unrelated topics
· remain independently understandable
Recommended size:
300–800 tokens
16. Semantic Chunking Best Practices
Good Chunk
Explains one concept deeply.
Contains supporting context.
Includes entity references.
Has semantic completeness.
Bad Chunk
Multiple unrelated topics.
Broken paragraphs.
Navigation-heavy text.
No semantic clarity.
17. Embeddings and Retrieval
Embeddings convert content into vectors.
These vectors allow semantic comparison.
Example:
“AI SEO”
≈ “LLM optimization”
≈ “Generative engine optimization”
Embeddings enable meaning-based retrieval.
18. Query Intent Mapping
Queries should map to:
· topics
· chunks
· entities
· services
· answer structures
Example:
{
“query”: “What is GEO?”,
“intent”: “definition”,
“targetChunk”: “chunk:geo-definition”
}
19. Retrieval Confidence Modeling
Every chunk should include confidence.
Example:
{
“retrievalConfidence”: 0.96
}
Confidence can depend on:
· authority
· freshness
· semantic relevance
· evidence quality
· citation quality
· retrieval history
20. Retrieval Priorities
Suggested priorities:
| Priority | Meaning |
| critical | Must retrieve whenever relevant |
| high | Strong retrieval preference |
| medium | Supporting retrieval |
| low | Contextual or fallback retrieval |
21. Context Window Engineering
LLMs have limited context windows.
Good RAG systems optimize:
· chunk ordering
· chunk diversity
· semantic continuity
· redundancy reduction
· authority prioritization
rag-index.json can help guide context assembly.
22. Canonical Retrieval Sources
Every major topic should have:
· preferred page
· preferred chunks
· preferred citations
Example:
{
“topic”: “Generative Engine Optimization”,
“canonicalSource”: “https://example.com/generative-engine-optimization/”
}
23. Retrieval Exclusion Rules
Not all content should be retrieved.
Exclude:
· outdated content
· thin content
· duplicate content
· weak pages
· low-confidence chunks
· obsolete services
Example:
{
“exclude”: true,
“reason”: “outdated content”
}
24. Freshness Modeling
Freshness influences retrieval quality.
Important for:
· AI trends
· software documentation
· pricing
· policies
· industry changes
Recommended metadata:
{
“lastUpdated”: “2026-05-13”,
“freshnessScore”: 0.92
}
25. Hybrid Retrieval Systems
Modern retrieval systems often combine:
Dense Retrieval
Vector similarity.
Sparse Retrieval
Keyword matching.
Hybrid Retrieval
Combines both.
rag-index.json should support hybrid systems.
26. Relationship With Vector Databases
The file can guide:
· vector indexing
· embedding grouping
· namespace organization
· chunk prioritization
· semantic clustering
Common vector databases:
· Pinecone
· Weaviate
· Milvus
· Chroma
· Qdrant
· Vespa
· Elasticsearch vector search
27. Recommended Semantic Categories
Suggested categories:
Definition
Guide
Comparison
Case Study
Research
Tutorial
Service
FAQ
Methodology
Framework
Checklist
Example
Glossary
Reference
28. Context Assembly Rules
A good retrieval system should:
· prefer authoritative chunks
· preserve semantic flow
· avoid duplicate ideas
· maximize relevance
· prioritize canonical explanations
Example:
{
“contextAssembly”: {
“maxChunks”: 5,
“preferCanonical”: true,
“allowSupportingEvidence”: true,
“avoidDuplicateConcepts”: true
}
}
29. Query Expansion
AI systems often expand queries semantically.
Example:
AI SEO
→ GEO
→ LLM Optimization
→ AI Search Visibility
The index should support semantic equivalents.
30. Relationship With GEO
rag-index.json is one of the most important GEO assets.
Because retrieval determines:
· whether content appears in answers
· whether citations happen
· whether context is accurate
· whether authority is recognized
Without retrieval:
there is no answer inclusion.
31. Common Mistakes
Mistake 1: Indexing Entire Pages
RAG should optimize chunks.
Mistake 2: Weak Chunk Boundaries
Broken semantics damage retrieval.
Mistake 3: No Canonical Sources
AI systems may retrieve weak pages.
Mistake 4: No Authority Weighting
All chunks are not equally valuable.
Mistake 5: Retrieval Noise
Too many irrelevant chunks reduce answer quality.
Mistake 6: No Freshness Metadata
Outdated content may dominate retrieval.
32. Best Practices
32.1 Use Stable Chunk IDs
Example:
chunk:geo-definition
chunk:llm-optimization-overview
32.2 Optimize for Embeddings
Write semantically complete chunks.
32.3 Prioritize Authority
Higher-authority chunks should rank higher.
32.4 Maintain Topic Clusters
Related chunks should remain connected.
32.5 Use Canonical Retrieval URLs
Every major topic needs a primary source.
32.6 Maintain Freshness
Update retrieval metadata regularly.
32.7 Use Query Intent Modeling
Different intents require different chunks.
33. Enterprise-Level Use Cases
AI Search Engines
Answer generation and citations.
Enterprise Knowledge Systems
Internal document retrieval.
AI Customer Support
Support answer grounding.
Research Systems
Evidence retrieval.
SaaS AI Assistants
Contextual help systems.
Ecommerce AI
Product recommendation retrieval.
34. Relationship With Answer Engines
Answer engines require:
· retrievable facts
· contextual grounding
· canonical definitions
· citation-ready chunks
The RAG index directly supports answer generation.
35. Retrieval Metrics to Track
Recommended metrics:
· retrieval precision
· retrieval recall
· semantic relevance
· citation rate
· hallucination rate
· chunk usage frequency
· answer confidence
· retrieval latency
· embedding quality
36. Recommended Update Frequency
| Asset | Frequency |
| Chunk metadata | Monthly |
| Retrieval priorities | Quarterly |
| Query mappings | Monthly |
| Freshness review | Monthly |
| Canonical sources | Quarterly |
| Retrieval testing | Continuous |
37. Full Reusable Prototype JSON Structure
{
“metadata”: {
“fileType”: “rag-index”,
“version”: “1.0.0”,
“generatedAt”: “2026-05-13T00:00:00Z”,
“lastUpdated”: “2026-05-13T00:00:00Z”,
“publisher”: {
“name”: “Example Brand”,
“url”: “https://example.com”
},
“description”: “Machine-readable retrieval orchestration index for semantic retrieval and RAG systems.”
},
“retrievalSettings”: {
“defaultChunkSize”: 500,
“maxContextChunks”: 5,
“preferredRetrievalMode”: “hybrid”,
“semanticThreshold”: 0.78,
“preferCanonicalSources”: true,
“allowSupportingEvidence”: true,
“avoidDuplicateContexts”: true
},
“topics”: [
{
“topicId”: “topic:generative-engine-optimization”,
“name”: “Generative Engine Optimization”,
“canonicalSource”: “https://example.com/generative-engine-optimization/”,
“retrievalPriority”: “critical”,
“authorityWeight”: 0.96,
“freshnessScore”: 0.93,
“semanticAliases”: [
“GEO”,
“AI SEO”,
“LLM Optimization”
],
“queryIntents”: [
“definition”,
“guide”,
“comparison”,
“implementation”
],
“preferredChunks”: [
“chunk:geo-definition”,
“chunk:geo-benefits”,
“chunk:geo-vs-seo”
]
}
],
“queryMappings”: [
{
“query”: “What is GEO?”,
“intent”: “definition”,
“targetTopic”: “topic:generative-engine-optimization”,
“preferredChunks”: [
“chunk:geo-definition”
],
“fallbackChunks”: [
“chunk:geo-benefits”
],
“retrievalConfidence”: 0.98
},
{
“query”: “How to optimize for AI search?”,
“intent”: “implementation”,
“targetTopic”: “topic:ai-search-visibility”,
“preferredChunks”: [
“chunk:ai-search-optimization-framework”
],
“retrievalConfidence”: 0.94
}
],
“chunks”: [
{
“chunkId”: “chunk:geo-definition”,
“title”: “Definition of Generative Engine Optimization”,
“sourceUrl”: “https://example.com/generative-engine-optimization/”,
“chunkType”: “definition”,
“retrievalPriority”: “critical”,
“authorityWeight”: 0.97,
“retrievalConfidence”: 0.98,
“freshnessScore”: 0.94,
“semanticEntities”: [
“Generative Engine Optimization”,
“AI SEO”,
“LLM Optimization”
],
“embeddingMetadata”: {
“embeddingModel”: “text-embedding-model”,
“embeddingVersion”: “v2”,
“semanticDensity”: 0.91
},
“chunkSummary”: “Defines Generative Engine Optimization and explains how it improves AI discoverability and retrieval.”,
“preferredCitation”: “https://example.com/generative-engine-optimization/”,
“contextRules”: {
“preferEarlyInContext”: true,
“allowStandaloneRetrieval”: true,
“avoidPartialRetrieval”: true
}
},
{
“chunkId”: “chunk:geo-vs-seo”,
“title”: “Difference Between GEO and Traditional SEO”,
“sourceUrl”: “https://example.com/generative-engine-optimization/”,
“chunkType”: “comparison”,
“retrievalPriority”: “high”,
“authorityWeight”: 0.93,
“retrievalConfidence”: 0.91,
“semanticEntities”: [
“SEO”,
“GEO”,
“AI Search”
]
}
],
“semanticClusters”: [
{
“clusterId”: “cluster:geo”,
“name”: “Generative Engine Optimization Cluster”,
“primaryTopic”: “topic:generative-engine-optimization”,
“relatedTopics”: [
“topic:ai-seo”,
“topic:llm-optimization”,
“topic:semantic-search”
],
“preferredSources”: [
“https://example.com/generative-engine-optimization/”,
“https://example.com/ai-seo/”
],
“clusterPriority”: “critical”
}
],
“retrievalRules”: {
“prioritizeFreshContent”: true,
“prioritizeAuthority”: true,
“preferCanonicalPages”: true,
“allowCrossTopicRetrieval”: true,
“excludeLowConfidenceChunks”: true,
“minimumConfidenceThreshold”: 0.70
},
“exclusions”: [
{
“sourceUrl”: “https://example.com/old-content/”,
“reason”: “outdated content”,
“excludeFromRetrieval”: true
}
],
“contextAssembly”: {
“maxChunks”: 5,
“maxContextTokens”: 4000,
“preserveSemanticFlow”: true,
“avoidRedundantChunks”: true,
“preferAuthoritativeChunks”: true,
“preferCanonicalDefinitions”: true
},
“citationPolicy”: {
“allowCitation”: true,
“canonicalDomain”: “https://example.com”,
“preferredCitationStyle”: “canonical-url”,
“topicCitationRules”: [
{
“topic”: “Generative Engine Optimization”,
“preferredSource”: “https://example.com/generative-engine-optimization/”
}
]
},
“maintenance”: {
“maintainedBy”: “AI Retrieval Team”,
“reviewFrequency”: “monthly”,
“lastReviewed”: “2026-05-13”,
“nextReview”: “2026-06-13”
}
}
38. ThatWare-Specific Strategic Direction
For ThatWare, the RAG index should heavily prioritize:
Generative Engine Optimization
AI SEO
LLM Optimization
Semantic SEO
Entity SEO
Knowledge Graph Optimization
AI Search Visibility
Recommended retrieval priorities:
| Topic | Suggested Priority |
| GEO | critical |
| AI SEO | critical |
| LLM Optimization | high |
| Semantic SEO | high |
| Entity SEO | high |
| Technical SEO | medium |
ThatWare should structure retrieval around:
· educational definitions
· implementation frameworks
· comparison guides
· methodology explanations
· research-backed content
· case studies
· technical architecture
The goal is not just ranking.
The goal is:
Becoming the preferred retrieval source for AI-generated answers.
39. Final Strategic Summary
rag-index.json should be treated as the retrieval brain of an AI-optimized website.
It defines:
· what content should be retrieved
· how retrieval should happen
· which chunks matter most
· how semantic matching should work
· how context should be assembled
· which sources should be prioritized
· how AI systems should build grounded answers
For GEO and AI-native search infrastructure, this file can become one of the most important components of semantic discoverability.
Without retrieval optimization, even excellent content may never appear in AI answers.
A properly designed rag-index.json transforms a website from merely searchable into semantically retrievable, contextually usable, citation-ready, and AI-answer optimized.
