SUPERCHARGE YOUR ONLINE VISIBILITY! CONTACT US AND LET’S ACHIEVE EXCELLENCE TOGETHER!
Search used to feel like a machine you could “solve.”
Type the right words. Put those words in the right places on a page. Earn enough links. Watch the rankings move. For more than two decades, the dominant mental model of search was mechanical: search engines index pages, match keywords, and rank results. That model wasn’t entirely wrong—but it was incomplete. And the parts it got wrong are now collapsing fast.

Today, search is changing shape. Not because people stopped searching, but because the web became too big, language became too flexible, and user needs became too complex for a system built around keywords and indexes. We are entering a world where the future of search isn’t indexed—it’s interpreted, predicted, and quantum-influenced. Search engines are learning to behave less like librarians and more like intelligent agents: systems that don’t just retrieve documents, but try to understand what you mean.
This is the shift from queries to intent graphs—from isolated keywords to networks of meaning.
The End of the Keyword Era

The Illusion of Control in Keyword-Based Search
Keyword-based search made people feel powerful because it seemed predictable.
If you searched “best running shoes,” you got pages optimized around “best running shoes.” If you wrote an article targeting that phrase—put it in the title, headings, meta description—you could often climb to the top. It looked like a neat equation: keyword in → keyword out. The internet became a place where language operated like a set of levers.
That’s why keywords felt deterministic. They gave creators, marketers, and even users a sense of control. You could measure them. Track them. Compare them. Build dashboards and strategies around them. Entire industries formed around keyword research tools, ranking trackers, and on-page optimization checklists. If you believed search worked like a direct matching engine, then success became an engineering problem.
But underneath that predictability was something fragile: the assumption that words are stable containers of meaning.
They aren’t.
Human thought is messy. People don’t think in keywords. They think in goals, fears, constraints, context, and urgency. A person typing “best running shoes” might be:
- training for a marathon and worried about injury,
- recovering from plantar fasciitis,
- shopping under a strict budget,
- looking for shoes for trail vs road,
- needing something available locally today.
The keyword stays the same. The meaning changes dramatically.
Ranking formulas amplified the illusion further. When you could see ranking changes after tweaking title tags or adding internal links, it created the impression of causality: I did X, Google rewarded me with Y. And for years, at scale, that was often true enough.
But it wasn’t because search engines truly “understood” your keyword. It was because the system was forced to treat language like a proxy for meaning—and proxies only work until they don’t.
That mismatch between human intent and keyword logic is at the heart of why this era is ending. Keywords were a convenient interface, not a faithful representation of thought. Search engines used them because they were computable, not because they were accurate.
Now that engines have better tools—semantic embeddings, large language models, behavioral prediction—they are no longer confined to the keyword-as-truth approach. They can move closer to how people actually think.
And once that happens, the old sense of control disappears.
The Cracks in Indexed Search
The second big reason the keyword era is fading is structural: indexed search is hitting its limits.
The web has exploded in volume, speed, and redundancy. Millions of new pages are created every day. Content is republished, paraphrased, spun, localized, summarized, and generated by machines. The result is not just more information—it’s more repetition of the same meaning dressed in different words.
Indexing was designed for a world where documents were comparatively scarce and language was comparatively stable. In that world, it made sense to crawl, store, and rank pages like a searchable library.
But today, indexing runs into three core cracks:
1) Explosion of content vs finite indexing capacity
Even the largest search engines can’t treat every page equally. Crawl budgets exist. Indexing delays exist. Some content is never indexed at all. The web is now too vast to be fully captured in a neat, up-to-date map.
2) Duplicate meanings and paraphrase inflation
In a keyword world, creators learned to produce “unique” pages by changing surface wording while keeping the same underlying message. Now AI tools can do that at industrial scale. The internet is drowning in semantic duplicates—pages that differ in phrasing but not in usefulness.
3) Semantic noise destroys “string matching”
When millions of pages target the same keyword, the signal-to-noise ratio collapses. The system can’t rely on exact terms anymore because exact terms are everywhere. If everyone uses the same keywords, keywords stop being discriminators.
At scale, “matching strings” becomes a weak strategy. It’s like trying to find the best restaurant in a city by searching menus for the word “delicious.” You’ll find the word everywhere, but it doesn’t tell you what you need to know.
This is why search engines are shifting away from the idea that indexing is the core value. Indexing is becoming a commodity: necessary infrastructure, but not the intelligence layer.
The intelligence layer is now about interpreting meaning and predicting what will satisfy the user—even if that means synthesizing answers rather than pointing to ten blue links.
A Paradigm Shift: Search as Meaning Interpretation
Once you see the cracks, the new direction becomes obvious: search engines are evolving from retrieval systems into cognitive systems.
A retrieval system is essentially an advanced filing cabinet: store documents, fetch the most relevant ones. A cognitive system does something more human-like: it tries to model what you want, what you already know, what you might need next, and what kind of answer will resolve your uncertainty.
This is the world hinted at by the statement:
“The future of search isn’t indexed—it’s interpreted, predicted, and quantum-influenced.”
- Interpreted means the engine does not treat your query as literal instructions. It treats it as evidence of a deeper intent.
- Predicted means it doesn’t only answer what you asked. It forecasts where your intent is going next and shapes the experience accordingly.
- Quantum-influenced (conceptually) means it accepts ambiguity and probability as first-class citizens. Instead of assuming your query has one meaning, it can hold multiple possible meanings in parallel—until your behavior clarifies which one matters.
This is where intent graphs enter.
Traditional search assumes a linear pipeline:
query → matching documents → ranked list
Intent-graph search assumes something more like:
query + context + behavior → intent network → best path to satisfaction
An intent graph is a map of meaning. It’s not just a model of what words appear on pages; it’s a model of what users are trying to accomplish, what sub-goals they explore, and how intents connect.
Think of it like this:
- In keyword search, the unit is the query string.
- In modern search, the unit is the intent state.
A single query can correspond to many intent states. And a single intent state can be expressed through many different queries. The engine’s job becomes less about matching text and more about navigating meaning.
So the core thesis is simple but disruptive:
The future of search isn’t “What documents match this query?”
It’s “What does this human mean, and what path resolves it?”
That’s why the shift from queries to intent graphs isn’t just a feature upgrade. It’s a foundational change in what “search” even is.
What Is a Query, Really?
For decades, search engines have treated the query as the primary unit of understanding—a neat string of words typed into a box, assumed to represent a user’s need. But a query was never the need itself. It was merely a compressed linguistic artifact, a rough approximation of a much richer mental state. As search systems evolve from retrieval engines into interpretive intelligence systems, the limitations of queries are becoming impossible to ignore.
To understand why modern search is moving beyond keywords, we first need to understand what a query truly is—and what it is not.
Queries as Linguistic Proxies for Thought
Human thought is not linear, precise, or keyword-driven. It is contextual, emotional, and often contradictory. When a person types a query into a search engine, they are not expressing their full intent; they are translating a complex internal state into the smallest possible linguistic form that a machine might understand.
This compression happens for several reasons:
- Humans optimize for speed and effort, not clarity
- They assume the system will “figure it out”
- They are often unsure of what they actually need
As a result, queries become lossy representations of intent.
Consider how much gets stripped away in this translation:
- Context: Why the question is being asked right now
- Emotion: Anxiety, excitement, confusion, urgency
- Constraints: Budget, time, risk tolerance, prior knowledge
- Stage of thinking: Exploration vs decision vs validation
Take the common query: “best laptop.”
On the surface, it looks simple. But beneath it may exist multiple, overlapping intent layers:
- “I need a reliable work laptop under a tight deadline”
- “I’m overwhelmed by choices and want reassurance”
- “I want the best value, not necessarily the most powerful device”
- “I don’t yet know what specs actually matter to me”
The query does not encode any of this. It is merely a shortcut, a thin linguistic wrapper around a multidimensional cognitive state. Traditional search systems pretended this wrapper was sufficient. Modern AI systems know better.
The Ambiguity Problem
Because queries are compressed representations, ambiguity is inevitable. The same query can mean entirely different things depending on the user, situation, and moment in time.
For example:
- “Apple” could signal interest in a company, a product, a stock, or a fruit
- “Java” could mean a programming language, a runtime environment, or a cup of coffee
- “Best laptop” could imply research, purchase, comparison, or validation
Traditional search engines treated this ambiguity as a problem to be eliminated. Their goal was to disambiguate as quickly as possible and return a ranked list that assumed a single “correct” interpretation. Any uncertainty was considered noise.
This approach worked when:
- The web was smaller
- Queries were simpler
- Users were willing to reformulate repeatedly
But ambiguity is not an error in human language—it is a signal of incomplete intent formation. Modern AI-driven search systems recognize that users often don’t yet know what they want. Ambiguity reveals exploration, hesitation, and evolving understanding.
Instead of collapsing ambiguity, AI systems now:
- Maintain multiple intent hypotheses simultaneously
- Observe interaction patterns to refine understanding
- Treat ambiguity as a probabilistic space, not a flaw
In this sense, ambiguity becomes informative. It tells the system not just what the user asked, but how uncertain they are.
Why Queries Are an Outdated Interface
As search evolves, it is becoming clear that the query itself is an outdated interface, not a fundamental requirement.
Several shifts are driving this change:
Voice and conversational input
Spoken language is less structured and more contextual than typed queries. Users ask full questions, change their minds mid-sentence, and rely on shared context. This breaks keyword-centric models entirely.
Multimodal and passive signals
Search is increasingly informed by images, location, device state, browsing behavior, and time-based context. A user may never type a query at all, yet their intent can still be inferred.
AI assistants and agents
When an AI assistant intermediates between the user and the web, the assistant handles intent interpretation internally. The user expresses goals, not queries. The system decides what to search, when, and how.
In this emerging paradigm, queries become optional. They are one of many signals, not the central one. Search shifts from “What did the user type?” to “What is the user trying to resolve?”
The future of search is not about better queries—it’s about systems that no longer need them. Queries were a workaround for limited machines. As machines learn to interpret meaning directly, the query fades from center stage, replaced by something far closer to human understanding: intent.
Intent: The Atomic Unit of Modern Search

If keywords were the “letters” of traditional search, intent is the sentence—the meaning that survives even when the words change. Modern search engines are steadily moving away from treating a query as a literal string to match and toward treating it as a compressed expression of a deeper goal. That’s why intent is becoming the smallest useful unit for understanding users: not what they typed, but what they are trying to accomplish, how they feel about it, how soon they need it, and how much uncertainty they’re willing to tolerate.
Defining Intent Beyond “Informational / Transactional”
For years, marketers and SEOs relied on tidy intent buckets: informational, navigational, transactional, and sometimes commercial investigation. Those categories weren’t useless—they were just too blunt for what search has become.
The limitation is obvious once you test them against real human behavior. Take the query: “best protein powder.”
Is it informational? Sure. Transactional? Also yes. But that framing misses the real question: best for whom, under what constraints, with what anxieties? One person is looking for a product to buy this week; another is comparing side effects because they have a sensitive stomach; a third wants vegan options; a fourth is training for a marathon and is worried about doping rules. Same query, completely different needs.
That’s where multi-dimensional intent becomes a better lens—because human intent is rarely one-dimensional.
Multi-dimensional intent includes layers like:
- Cognitive intent (What does the user want to know or figure out?)
This is the “thinking” goal: learning, comparing, troubleshooting, verifying, building a mental model.
Example: “how does creatine work” isn’t just “informational”—it may be exploratory learning, validation, or myth-busting depending on the person.
- Emotional intent (What emotional state is driving the search?)
People search when they feel something: anxiety, excitement, frustration, curiosity, urgency, fear of missing out, fear of making a mistake.
Example: “symptoms of chest pain” is not only informational—it’s frequently reassurance-seeking.
- Temporal intent (When does the user need the answer or outcome?)
Some searches are immediate (“near me”, “open now”, “today”), others are long-horizon (“best universities”, “retirement plan”), and many sit in between (“in the next 3 months”).
The same topic changes drastically based on time pressure. “Best laptop” for a purchase today requires availability and quick comparisons; for next quarter it requires future-proofing and release cycles.
- Risk tolerance (How safe must the answer be?)
Some users are okay with experimentation; others need certainty. High-stakes categories (health, finance, legal, security) demand higher caution, better sourcing, and clearer uncertainty markers.
Example: “invest in small caps” may be research for someone with high risk tolerance—or it may be someone terrified of losing savings and looking for conservative guidance.
When search engines model intent this way, they aren’t just classifying queries—they’re estimating a user state. That user state determines what kind of response is most helpful: a tutorial, a comparison table, a direct recommendation, a caution-first explanation, or a step-by-step decision path.
Intent as a Dynamic State, Not a Category
A bigger shift is happening beneath the surface: intent isn’t fixed even within a single session. It morphs as the user learns, doubts, refines constraints, and discovers tradeoffs.
Think of a typical search journey:
- “best CRM for small business”
- “HubSpot vs Zoho pricing”
- “how hard is HubSpot to set up”
- “Zoho CRM review reddit”
- “HubSpot onboarding cost”
- “CRM for 5 users under $50”
This isn’t one intent—it’s a sequence of micro-intents:
- exploration → comparison → feasibility check → trust validation → cost clarity → constraint optimization
Traditional intent taxonomies struggle here because they assume a query belongs to a stable bucket. But modern search increasingly behaves like it’s tracking a moving target.
That’s why static intent classification fails:
- It ignores the journey structure (how intent changes over time)
- It treats queries as independent events, not part of a chain
- It misses the transitions that signal what the user needs next
In an intent-graph world, the search engine isn’t just asking “What type of query is this?”
It’s asking: “What state is this user currently in—and what state are they likely to move into next?”
This matters because the best result isn’t always the most relevant to the words. It’s the most relevant to the next decision the user needs to make.
Behavioral Signals as Intent Inputs
If intent is a hidden state, then search engines need evidence to infer it. That evidence comes from behavioral and contextual signals—not just what users type.
Some of the strongest behavioral intent signals include:
- Click behavior
Which result did they choose? Was it a brand? A forum? A video? A government site? Click choice often reflects trust preference and task type.
- Dwell time
How long did they stay before returning? Long dwell time can imply satisfaction—or it can imply confusion if followed by multiple reformulations. Engines interpret dwell time alongside other signals.
- Reformulations and query chains
When users rephrase, add constraints, or narrow scope, they reveal the shape of the intent.
Example: “best earbuds” → “best earbuds for calls” → “best earbuds for calls under $100” = constraint discovery.
Then there are contextual signals that reshape meaning:
- Device (mobile vs desktop)
Mobile queries skew toward immediacy and location; desktop often indicates deeper research.
- Time (hour, day, season)
“Restaurants” at 8 PM means something different than at 11 AM. “Gifts” in December has a different urgency curve.
- Location
“Best internet provider” is fundamentally local. Even “best colleges” can become regional when combined with behavior.
And finally, there’s the most powerful layer:
- Longitudinal patterns vs single-session data
A single query is a snapshot. A user’s history is a storyline.
Engines can infer whether a person is a beginner or advanced, whether they repeatedly research a topic, whether they tend to buy quickly or deliberate, whether they prefer certain sources, and what they consider “good enough.”
This is where “search” starts to look less like a database query and more like inference under uncertainty. The engine is constantly updating its belief about what the user means—using the query as just one of many signals.
Bottom line: modern search treats intent as the true payload and the query as a noisy wrapper. And the future hinted by your thesis—interpreted, predicted, and quantum-influenced search—is essentially this: systems that model human meaning as probabilities, not categories.
From Keywords to Intent Graphs
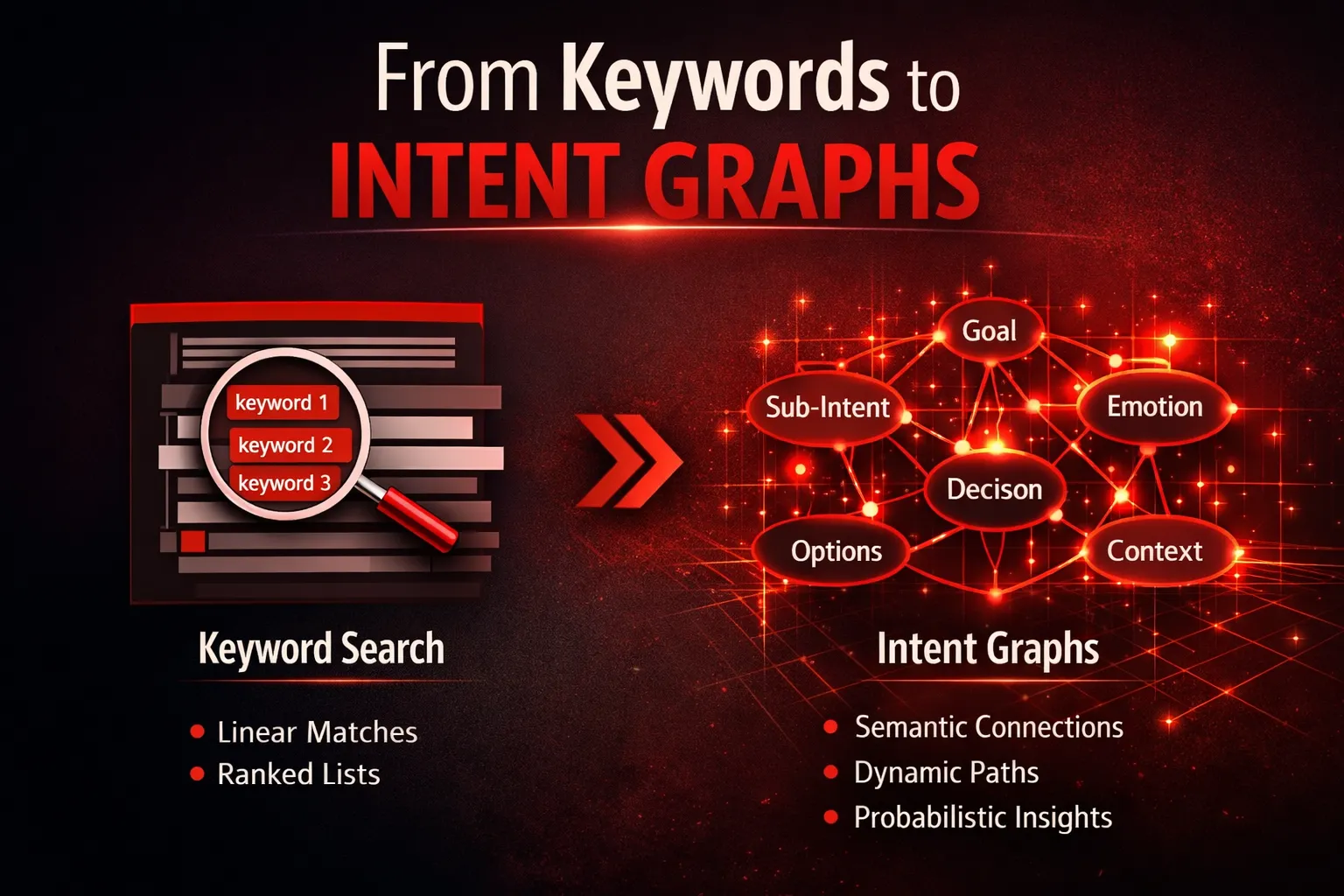
For most of search history, a query was treated like a string-matching problem: you typed words, the engine looked for pages containing those words (plus a lot of ranking math), and you got a list.
But humans don’t think in strings. We think in goals, constraints, and uncertainty. And that’s why search is shifting from “keywords → pages” toward meaning → intent pathways.
An intent graph is the structural upgrade that makes this shift possible.
What Is an Intent Graph?
An intent graph is a living map of what a user is trying to accomplish, not just what they typed.
If you imagine the old model as:
Query → Index → Ranked Links,
the new model looks more like:
User state → Intent possibilities → Best next step.
Nodes: goals, sub-goals, beliefs, uncertainties
In an intent graph, nodes aren’t webpages or entities—they’re mental states and objectives. Typical node types include:
- User goals: the destination (“choose the right AI SEO tool”)
- Sub-goals: intermediate steps (“compare features,” “see pricing,” “read unbiased reviews”)
- Beliefs: assumptions the user currently holds (“AI SEO tools are mostly hype”)
- Uncertainties: what they don’t know yet (“Do I need this if I already use Ahrefs?”)
This is crucial: modern search engines are becoming less like librarians and more like guides, identifying what the user hasn’t resolved yet and steering them through it.
Edges: relationships, probabilities, transitions
The edges in an intent graph represent how users tend to move between nodes, such as:
- Relationships: “pricing research” relates to “trial signup,” “feature comparison” relates to “tool shortlist”
- Transitions: the common next step after one intent is satisfied
- Probabilities: how likely a user in node A will need node B next
Edges are what make the graph dynamic. They allow the engine to estimate:
“What’s the most helpful next move for this person right now?”
Intent graphs vs knowledge graphs
A knowledge graph represents the world.
An intent graph represents the user.
- Knowledge graphs store entities and facts (Google, Semrush, pricing tiers, founders, categories).
- Intent graphs store goals and journeys (learn basics, validate trust, compare ROI, decide fast).
A knowledge graph can tell you what an AI SEO tool is.
An intent graph can infer why you’re asking, what you’re worried about, and what you’ll need next to decide.
In other words:
Knowledge graphs explain reality. Intent graphs explain desire.
How Search Engines Build Intent Graphs
Intent graphs aren’t built from one signal. They’re built from many weak signals that become strong when combined.
Aggregated behavioral data
The biggest source is still behavior—at scale.
Search engines learn from patterns like:
- query reformulations (“AI SEO tools” → “AI SEO tools for agencies” → “Semrush AI vs Surfer”)
- click paths and backtracking (clicked, returned quickly, tried something else)
- dwell time (did the result actually satisfy the intent?)
- follow-up actions (download, signup, comparison searches, brand searches)
Importantly, it’s not just “what people clicked,” but what they did next.
That “next” is how edges get formed and weighted.
Semantic embeddings and vector similarity
Behavior alone can’t interpret meaning well—especially with new queries. That’s where semantic embeddings come in.
Embeddings transform text into vectors so the engine can reason about similarity like:
- “best AI SEO tools” ≈ “AI content optimization platforms”
- “programmatic SEO AI” ≈ “AI for scalable landing pages”
This matters because users rarely phrase the same intent the same way. Embeddings let search engines treat language as meaning-space, not keyword-space.
So even if a query has never been seen before, the engine can still place it near relevant intent nodes because it “lives” in the same semantic neighborhood.
Reinforcement learning loops
Modern ranking systems are increasingly trained as decision systems: “choose the best response to maximize satisfaction.”
Reinforcement learning introduces a feedback loop:
- the engine tries a response (a result type, a summary, a shortlist, a comparison)
- it observes whether the user outcome improved (shorter journeys, fewer reformulations, higher satisfaction signals)
- it updates the policy (how it chooses next time)
This is where intent graphs become adaptive: edges shift as the engine learns which pathways produce the fastest resolution of uncertainty.
In simple terms: the system learns not just what’s relevant, but what’s helpful.
Why Graphs Beat Lists
A ranked list assumes a single truth: the best page is #1. But real decision-making rarely works like that.
Non-linear thinking vs ranked results
Humans don’t think linearly. We jump between:
- learning → evaluating → doubting → verifying → deciding
- “what is it?” → “can I trust it?” → “is it worth it?” → “what happens if I choose wrong?”
A list can’t represent that. A graph can.
An intent graph supports branching: different users can enter the same query with different goals and exit through different paths.
Multiple valid paths to satisfaction
With a list, the engine guesses one dominant intent and ranks accordingly.
With a graph, the engine can recognize that many intents are plausible at once and offer multiple routes, like:
- “Want a quick shortlist?”
- “Want a deep comparison?”
- “Want proof this works?”
- “Want pricing + ROI?”
This is why modern SERPs increasingly show mixed formats: comparisons, FAQs, product snippets, forum threads, and AI summaries. That’s the engine acknowledging: “Your intent may not be singular.”
Probability-weighted outcomes
An intent graph doesn’t just store connections—it stores likelihoods.
Instead of ranking “the best result,” the engine estimates:
- which intent the user is most likely in
- which next step is most likely to reduce uncertainty
- which information format is most likely to satisfy
The result is more like a probability distribution of helpfulness than a single ordered list.
That shift aligns with the broader idea that the future of search isn’t indexed—it’s interpreted and predicted. Rankings become a crude approximation when the system can compute “most likely helpful next step” directly.
Example: A Real-World Intent Graph Walkthrough (Query: “AI SEO tools”)
Let’s take a query that looks simple: “AI SEO tools.”
In the old world, this meant: show me pages optimized for “AI SEO tools.”
In the intent-graph world, it means: which of several intent states is this person in?
Step 1: The engine expands plausible intents
The query could represent many underlying goals, including:
- Learning vs buying
- Learning: “What are AI SEO tools? What do they do?”
- Buying: “Which tool should I pick this week?”
- Curiosity vs urgency
- Curiosity: “Exploring what’s out there.”
- Urgency: “Need a tool for a client / campaign right now.”
- Skepticism vs trust
- Skepticism: “Is this hype? Does it actually work?”
- Trust: “I already believe; just show me options.”
Each of these becomes a cluster of nodes in the intent graph.
Step 2: The engine uses context to choose a starting node
The engine looks for signals:
- Is this query part of a longer session?
If earlier searches were “what is topical authority” or “how does Surfer work,” that suggests a learning node.
- Did the user previously search brands or pricing?
“Surfer pricing,” “Semrush AI,” “Jasper alternatives” suggests a buying node.
- Do they reformulate quickly?
Quick reformulations often signal uncertainty or dissatisfaction.
- Do they click reviews or case studies?
That’s usually skepticism or risk mitigation.
From these signals, the engine picks a most likely starting node, but keeps alternatives active (because uncertainty is inherent).
Step 3: It serves content as pathways, not pages
Now the engine chooses formats aligned to the detected intent:
- If learning: definitions, beginner guides, conceptual explanations
- If buying: comparisons, pricing tables, “best for X” breakdowns
- If skeptical: independent reviews, case studies, community discussions
- If urgent: quick shortlist + “start here” recommendations
The SERP becomes a multi-lane highway, not a single ranked staircase.
Step 4: The engine adjusts the graph in real time
As the user interacts, the system updates probabilities:
- If they click a “best tools” list and then search “tool name + pricing,” it increases the likelihood they’re moving toward a purchase node.
- If they click a case study and then search “AI SEO tools inaccurate,” it increases the likelihood they’re in a skepticism branch.
- If they click “what is” content and spend time, it reinforces the learning branch.
In effect, the engine is continuously answering:
“Where are you in the decision graph right now?”
The Big Shift
This is what it means when we say:
The future of search isn’t indexed—it’s interpreted, predicted, and quantum-influenced.
- Interpreted: the engine decodes intent, not strings
- Predicted: it anticipates the next node you’ll need
- Quantum-influenced: multiple intents can coexist until interaction collapses them into a clearer path
In the old model, your query was the command.
In the new model, your query is just the first clue.
And intent graphs are how search engines learn to “think” in meanings—one probabilistic pathway at a time.
Interpretation Over Indexing

For most of the internet’s history, search has been a logistics problem: crawl pages, index words, return matches. That model worked when the web was smaller, language was simpler, and users were willing to browse a list of links. But the center of gravity is shifting. In modern systems, indexing is still useful—but it’s no longer the main event.
What’s taking its place is a more human-like capability: interpretation. Search engines are increasingly acting less like librarians who fetch books and more like analysts who infer what you really mean, decide what information matters, and assemble an answer that reduces uncertainty—even when the “perfect page” doesn’t exist.
That’s why the future of search isn’t indexed—it’s interpreted, predicted, and (in an important conceptual sense) quantum-influenced.
Why Indexes Are Becoming Secondary
Indexes store content, not understanding
An index is a map from tokens to documents. At best, it can store associations: which pages contain which words, or which pages link to which entities. But an index doesn’t truly “know” what a passage means. It doesn’t understand nuance, implied intent, sarcasm, missing context, or what information is actually needed to satisfy the user.
Indexes are optimized for retrieval. Humans, however, search for resolution.
If someone searches “should I refinance now,” they’re not asking for a list of pages that include refinance and now. They’re asking for:
- what “now” means in a rate environment,
- the trade-offs that apply to their personal situation,
- and what decision would reduce regret.
That difference—between matching and meaning—is where the index starts to feel like a blunt instrument.
LLMs and embeddings as compressed meaning stores
This is where modern representations change the game. Instead of storing web pages as a giant list of documents and terms, search systems increasingly rely on embeddings—numeric representations of meaning. Embeddings compress language into vectors where similarity reflects semantic closeness.
That matters because meaning isn’t a string problem. It’s a relationship problem:
- “best budget smartphone” is close to “cheap phone with good camera”
- “how to start running” is close to “beginner training plan for 5K”
- “symptoms of burnout” is close to “why I feel exhausted and numb”
An embedding-based system can connect those intents even when the words barely overlap. In other words, it’s not “finding the same words”—it’s “finding the same idea.”
Large language models add another layer: they can operate like meaning engines—not simply retrieving content, but transforming and summarizing it into structured knowledge. They don’t just store information; they can interpret, generalize, and explain.
Retrieval-augmented generation vs crawling
Classic crawling/indexing assumes that the answer lives somewhere as a page, and search should route you to it.
But in many modern search experiences, the user doesn’t want a route. They want the destination.
That’s why retrieval-augmented generation (RAG) is becoming so central. RAG flips the workflow:
- Retrieve relevant evidence (often using embeddings + lightweight indexes)
- Generate an answer by synthesizing and grounding it in that evidence
- Present the answer in an actionable, coherent form
In this setup, crawling and indexing are supportive infrastructure—still important, but no longer the final interface. The “product” becomes the interpretation layer: the ability to unify sources, resolve ambiguity, and deliver a response that actually helps.
Semantic Compression of the Web
Meaning clusters replacing document URLs
As embeddings and LLMs grow more capable, “the web” starts looking less like a collection of pages and more like a collection of meanings.
Imagine the internet reorganized not by URLs, but by clusters of intent:
- “how to learn Python”
- “Python vs JavaScript for beginners”
- “best projects to build after basics”
- “how long it takes to become job-ready”
In a meaning-first world, documents become raw material. The system cares less about which page said it and more about:
- what patterns emerge across credible sources,
- what the consensus is,
- and what information reduces the user’s uncertainty fastest.
So instead of ranking pages, the engine is increasingly ranking interpretations—and showing evidence only as needed.
Why the “best answer” may not exist as a page
This is the quiet truth most people miss: the best answer is often not written anywhere.
Some questions are inherently compositional:
- “What’s the best marketing strategy for a bootstrapped SaaS in India targeting US customers?”
- “How do I transition from QA to ML engineering with limited math background?”
- “Which laptop should I buy if I travel a lot, edit videos occasionally, and hate fan noise?”
A single page might cover pieces, but rarely the whole. A purely indexed system struggles because it assumes one document can satisfy the intent. A meaning-based system assumes the opposite: answers are assembled.
This is where interpretation beats indexing. It can blend:
- general principles + current constraints,
- multiple trade-offs,
- user preferences implied from context,
- and “what to do next” guidance.
That assembled answer may be more valuable than any page—because it never existed until the user asked.
Search engines synthesizing responses
Synthesis is not just summarization. Summarization compresses one source. Synthesis integrates many sources into one coherent mental model.
Modern engines are moving toward:
- combining multiple viewpoints,
- extracting the most relevant parts,
- highlighting what’s uncertain,
- and providing a structured recommendation or explanation.
This is why you’re seeing more “direct answers,” “AI overviews,” and conversational responses: search is becoming an explanation engine, not a directory.
Search as Interpretation, Not Lookup
Interpreting what the user means to know
People rarely know how to ask what they actually need.
They ask:
- “best CRM” when they mean “CRM that my small team will actually adopt”
- “why is my website traffic down” when they mean “did I get hit by an update or is my tracking broken?”
- “is AI taking jobs” when they mean “am I personally at risk in the next 2 years?”
Interpretive search treats the query as a signal, not a specification. It tries to infer:
- what stage the user is in,
- what constraints matter,
- what the hidden fear/goal is,
- what “success” looks like.
This is also where the “predicted” part of the future-of-search quote fits in: systems learn patterns of how intents evolve, and they start anticipating the next question before it’s asked.
Resolving contradictions and uncertainty
The web is full of contradictions:
- two experts disagree,
- two studies have different outcomes,
- best practices change over time,
- advice depends on context.
Traditional search punts this problem to the user: “Here are ten links; you decide.” Interpretation-driven search takes responsibility for reducing uncertainty by doing things like:
- surfacing consensus and disagreement,
- stating assumptions (“this applies if…”),
- ranking confidence, not just relevance,
- showing what would change the recommendation.
In that sense, search becomes less like a lookup tool and more like a decision support system.
Contextual truth vs absolute truth
Indexed search implicitly treats truth like a static object: it exists in a document, and the document can be retrieved.
Interpretive search treats truth more like a contextual fit:
- what’s true for a beginner may not be true for an expert,
- what’s true in 2026 may not have been true in 2020,
- what’s true under one constraint flips under another.
This is where the “quantum-influenced” idea becomes useful—conceptually. In human reality, multiple potential interpretations can be “alive” at once until context collapses them into one. Search is moving toward managing that superposition:
- holding multiple meanings,
- weighing probabilities,
- and refining the answer as the user interacts.
So instead of “the best result,” you get “the best interpretation given what we know so far.”
Bottom line: indexing will remain necessary infrastructure. But it’s no longer the core intelligence. The intelligence is moving up the stack—into models that interpret intent, predict next needs, and synthesize answers from meaning clusters.
And that’s the shift: from search as retrieval to search as understanding.
Predictive Search: Intent Before Expression

The most radical shift in modern search is not how answers are retrieved, but when intent is recognized. Traditional search systems were fundamentally reactive: a user asked, the system responded. In contrast, predictive search systems aim to understand intent before it is fully expressed, sometimes even before the user is consciously aware of it. This transition marks the movement from search as a lookup mechanism to search as an anticipatory cognitive system.
From Reactive to Anticipatory Systems
In classical search models, intent was inferred only after a query was submitted. The system treated each query as an isolated event, largely ignoring what came before and what might come next. Predictive search breaks this assumption entirely. Instead of asking, “What does this query mean?”, modern systems increasingly ask, “What intent state is the user currently in, and where is it likely to evolve?”
Search engines now model intent as a trajectory, not a point. Every interaction—queries, clicks, dwell time, scrolling behavior, reformulations, even hesitation—feeds into a continuously updated intent state. This enables session-based forecasting, where the system predicts the user’s next likely question, decision, or need based on patterns observed across millions of similar journeys.
For example, a user researching “cloud security basics” may not explicitly ask about compliance, risk mitigation, or vendor comparisons—but predictive systems recognize that these intents commonly follow. The engine begins to surface content aligned with future intent states, effectively shortening the cognitive distance between question and resolution.
Underlying this capability are behavioral priors—statistical patterns learned from historical user behavior. These priors allow search engines to assign probabilities to possible next intents. Importantly, this is not personalization in the superficial sense of “showing similar content,” but a deeper probabilistic modeling of how human curiosity and decision-making typically unfold over time.
The Role of Probabilistic Models
Predictive search cannot function within rigid, deterministic frameworks. Human intent is inherently uncertain, incomplete, and often contradictory. As a result, modern search systems increasingly rely on probabilistic models rather than fixed ranking algorithms.
In this paradigm, search results are no longer a linear list ordered by relevance scores. Instead, they resemble likelihood distributions over possible answers, interpretations, or next steps. Each response carries an implicit confidence level based on how well it aligns with the system’s current intent model.
This is why we are seeing the gradual disappearance of traditional rankings. Rankings assume a single “best” answer for a given query. Probabilistic search assumes multiple plausible answers, each with varying degrees of usefulness depending on the user’s evolving context. The system’s goal shifts from choosing the answer to presenting the most probable resolution paths.
Confidence-weighted answers are a natural outcome of this approach. Search engines increasingly hedge, qualify, summarize trade-offs, and surface uncertainty—especially in complex or high-stakes domains. This behavior is not a weakness; it reflects a more honest representation of incomplete knowledge and competing interpretations.
Over time, as predictive accuracy improves, the distinction between “search result” and “recommendation” will blur entirely. What users experience as search will often be the output of probabilistic inference, not document retrieval.
Ethical and Cognitive Implications
The power to predict intent carries profound ethical and cognitive consequences. When systems anticipate needs, they don’t merely respond to behavior—they shape it. By surfacing certain possibilities earlier and suppressing others, predictive search can subtly influence what users consider, choose, or even believe.
This creates a fine line between assistance and manipulation. Helping a user reach clarity faster is beneficial. Nudging them toward predefined outcomes—commercial, ideological, or behavioral—raises serious concerns. The more accurate predictive systems become, the less visible their influence is to the user.
Transparency is therefore one of the greatest challenges of predictive search. Probabilistic reasoning is inherently opaque, even to its creators. Explaining why a particular answer, suggestion, or next step was shown becomes increasingly difficult as models grow more complex and context-dependent.
There is also a cognitive risk: over-reliance on anticipatory systems may reduce exploratory thinking. If search engines consistently predict and preempt our questions, users may engage less in curiosity-driven discovery and more in guided consumption.
Ultimately, predictive search forces a fundamental question: Should search engines optimize for efficiency of resolution, or for preservation of human agency? The answer will define not just the future of search, but the future of how humans interact with knowledge itself.
In a world where intent is predicted before it is spoken, search stops being a tool—and starts becoming a silent collaborator in human thought.
Quantum-Influenced Thinking in Search

The more search engines try to understand humans, the more they run into a fundamental problem: human intent does not obey classical logic. Traditional search systems were built on deterministic rules—if a query matches a document, return it; if it matches better, rank it higher. But human thinking is not deterministic, linear, or even internally consistent. To bridge this gap, modern search systems are increasingly borrowing ideas from quantum thinking—not in hardware, but in logic. These quantum-inspired models offer a far more realistic way to represent how people actually think, decide, and search.
Why Classical Logic Fails for Human Intent
Classical logic assumes stability: a user wants one thing, has one goal, and will choose the best answer. Human intent, however, rarely behaves this way.
First, humans routinely hold conflicting beliefs at the same time. A user searching for “AI replacing jobs” may be simultaneously curious, fearful, skeptical, and hopeful. They may want reassurance and evidence, optimism and warnings—all at once. Classical systems force these contradictions into a single intent category, losing nuance in the process. Modern search must account for the fact that users don’t resolve their internal conflicts before searching—they search because of them.
Second, human decision-making is non-binary. People don’t operate in yes/no states; they exist in gradients of confidence and uncertainty. Someone researching a product is rarely deciding between “buy” or “don’t buy.” Instead, they oscillate between interest and hesitation, logic and emotion, price and value. Classical logic expects crisp decisions, but human intent is probabilistic, fluid, and evolving.
Third, truth itself is contextual. What counts as a “correct” answer depends on time, situation, background knowledge, and even emotional state. The best explanation for a beginner is not the best explanation for an expert. Classical search treats truth as static; human cognition treats truth as situational. This mismatch is one of the core reasons traditional ranking systems struggle to satisfy users consistently.
Quantum Concepts Applied to Search (Conceptual, Not Technical)
To model this complexity, search systems are adopting quantum-inspired conceptual frameworks—not quantum physics in the literal sense, but ideas that better reflect uncertainty, multiplicity, and probability.
One such idea is superposition of intent. In quantum terms, a system can exist in multiple states at once until it is observed. Similarly, a user’s intent often exists in multiple states simultaneously. A single query can represent research, comparison, validation, and emotional reassurance all at once. Instead of forcing an early classification, modern search systems keep multiple intent interpretations active in parallel.
This leads to probability amplitudes instead of rigid rankings. Rather than deciding that result #1 is definitively better than result #2, modern systems assign likelihoods: this answer has a higher probability of satisfying the user given the current context. Results become weighted possibilities, not absolute winners. This is why rankings increasingly fluctuate, personalize, or collapse into synthesized responses.
The final step is the collapse of intent upon interaction. Just as observation collapses a quantum state, user interaction—clicking, scrolling, asking a follow-up question—resolves ambiguity. Each action provides a signal that sharpens the system’s understanding of what the user actually wants. Intent is not fully known at the query stage; it is revealed progressively through interaction.
Quantum-Inspired Algorithms Today
Importantly, these ideas are not theoretical or futuristic—they already shape modern search systems.
Search engines now perform parallel evaluation of multiple meanings using embeddings and vector spaces. A single query is mapped to many semantic neighborhoods at once, allowing the system to test different interpretations simultaneously. This is computationally expensive, but far more aligned with human cognition.
Another key principle is the exploration vs. exploitation trade-off. Should the system show what it is most confident will work (exploitation), or test alternative interpretations that might better satisfy the user (exploration)? Quantum-inspired approaches allow systems to balance both—delivering safe answers while still probing for better ones through diversity and variation.
Crucially, this matters even without true quantum hardware. These models run on classical machines but adopt probabilistic, non-deterministic thinking. The shift is philosophical before it is technological. Search engines are no longer trying to “find the right page.” They are trying to navigate uncertainty, reduce ambiguity, and adapt in real time to human complexity.
In this sense, quantum-influenced thinking is not about the future of computers—it is about the future of understanding. And search, more than any other system, sits at the center of that transformation.
What This Means for SEO, Content, and Brands

The shift from queries to intent graphs fundamentally rewrites the rules of visibility on the web. Search is no longer a system that rewards technical compliance with keyword formulas; it is becoming a meaning-driven intelligence layer that evaluates how well content satisfies human uncertainty. For SEO professionals, content creators, and brands, this represents not an evolution—but a structural break from the past.
The Death of Optimization for Keywords
For decades, SEO operated on a relatively simple assumption: if your content matched the words users typed, search engines would surface it. That assumption is rapidly collapsing. In an intent-graph-driven system, matching phrases no longer guarantees visibility, because phrases are no longer the primary unit of understanding.
Modern search engines interpret language through semantic embeddings, behavioral patterns, and contextual signals. Two pages can use entirely different vocabulary and still be treated as equivalent—or irrelevant—depending on how well they resolve the user’s underlying intent. Conversely, a page that perfectly matches a keyword may fail if it does not meaningfully advance the user’s goal.
This introduces a critical distinction: content relevance vs. semantic usefulness. Relevance answers the question, “Does this page appear to be about the topic?” Semantic usefulness asks, “Does this content reduce uncertainty, support decision-making, or move the user closer to resolution?” Intent graphs optimize for the latter. As a result, keyword density, exact-match headings, and traditional on-page tricks lose influence, while clarity, completeness, and contextual depth gain priority.
Optimizing for Intent Coverage
In an intent-first search ecosystem, optimization shifts from targeting keywords to mapping intent spaces. Instead of asking, “What terms should I rank for?” the more strategic question becomes, “What states of uncertainty does my audience experience, and how do those states evolve?”
Intent coverage means identifying the full range of motivations, concerns, and decision paths surrounding a topic. For example, a user researching “AI SEO tools” may simultaneously seek education, validation, risk assessment, comparisons, and implementation guidance. Content that addresses only one narrow angle may be semantically correct but strategically insufficient.
High-performing content in this model focuses on resolving uncertainty, not just delivering information. It anticipates follow-up questions, addresses objections, clarifies trade-offs, and contextualizes choices. This naturally leads to a depth-over-breadth strategy: fewer pages, but each one designed to satisfy multiple connected intents within the same graph. Long-form, cohesive resources outperform fragmented content because they align with how intent actually unfolds.
Brand as a Node in the Intent Graph
As search engines rely more on interpretation and prediction, brands themselves become critical signals within intent graphs. Trust, authority, and familiarity are not abstract marketing concepts; they function as probabilistic shortcuts in meaning-based systems.
When multiple answers appear semantically valid, search engines increasingly favor entities with established credibility. Brands act as stable nodes—recognized sources that reduce uncertainty without requiring exhaustive verification each time. This is why brands survive better than anonymous pages in AI-driven search: they carry accumulated behavioral, contextual, and reputational signals.
Entity-based visibility replaces page-level optimization. Search engines do not just rank content; they evaluate who is saying it. Consistent expertise, coherent topical focus, and recognizable authorship strengthen a brand’s position within intent graphs. In the future of search, visibility is not earned by gaming algorithms—but by becoming a trusted meaning provider within the system itself.
In an intent-driven world, SEO is no longer about being discoverable—it is about being dependable.
The Future of Search Interfaces
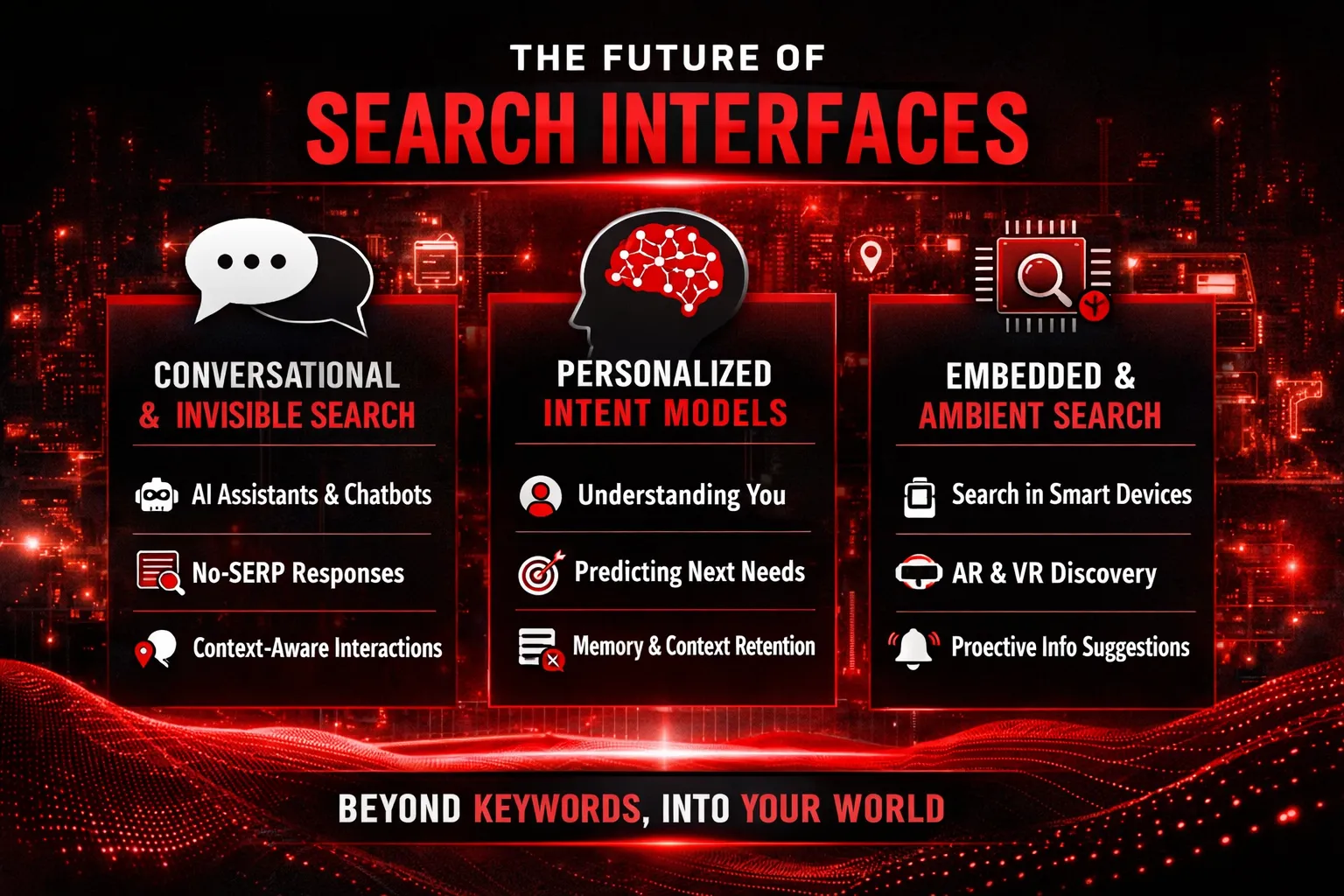
The way humans interact with search is undergoing a quiet but profound transformation. For decades, the search interface has been visually and conceptually dominated by the SERP—pages of ranked links designed for manual exploration. But as search engines evolve from retrieval systems into interpretive and predictive intelligence layers, the interface itself is beginning to dissolve. The future of search will not look like a page you visit. It will feel like a capability that surrounds you.
Conversational, Invisible, Embedded Search
The most visible change in search interfaces is that they are becoming less visible. Traditional SERPs are being replaced by conversational responses, synthesized answers, and contextual actions. Instead of asking a question and choosing from ten blue links, users increasingly receive a single, adaptive response that evolves as the conversation continues. Search is no longer a destination—it is a dialogue.
AI agents are central to this shift. These agents act as mediators between human intent and the vast complexity of information systems. Rather than exposing users to raw information, they interpret needs, ask clarifying questions, and deliver outcomes. In this model, search engines stop being tools and start behaving like collaborators. They don’t just retrieve information; they help users think.
Even more transformative is the rise of ambient discovery. Search is becoming embedded into everyday experiences—inside operating systems, applications, devices, and environments. Information surfaces at the moment of relevance, often without an explicit query. A reminder appears before you realize you need it. A recommendation arrives precisely when uncertainty emerges. Discovery becomes passive, contextual, and continuous.
Personal Intent Models
As interfaces fade, personalization becomes the primary differentiator. Future search systems will rely on deeply individualized intent models—dynamic representations of a user’s goals, preferences, constraints, and cognitive patterns. Instead of treating each search as an isolated event, engines will maintain persistent intent memory, learning from past behavior, decisions, and outcomes.
This enables search engines to “know” users in a functional sense—not just what they like, but how they think, decide, and change their minds. Meaning is no longer interpreted universally; it is customized. The same question asked by two people may yield entirely different responses, shaped by context, history, and inferred intent states.
In this future, search becomes less about asking the right question and more about being understood without needing to ask at all. The interface disappears, but intelligence becomes ever-present—quietly interpreting meaning, predicting needs, and guiding decisions in the background.
Conclusion: Search Is Becoming Cognitive
From Machines That Find to Systems That Understand
Search is no longer a mechanical process of locating documents that contain matching words. It is evolving into a cognitive layer of the internet—one that interprets, reasons, and contextualizes information before presenting it. Modern search systems are learning to understand meaning, not just retrieve matches. Instead of asking, “Which pages contain these terms?”, they ask, “What is the user actually trying to resolve?”
This shift marks the transition from search as infrastructure to search as intelligence. Meaning now outweighs matching. Context outweighs keywords. Probability outweighs certainty. Search engines increasingly operate like reasoning systems that synthesize understanding across vast semantic spaces, rather than librarians pointing to indexed shelves.
The New Mental Model
This evolution demands a fundamental change in how creators, brands, and strategists think about visibility. The old question—“How do I rank?”—belongs to a world where search engines evaluated pages in isolation. In a cognitive search environment, the better question is “How do I reduce user uncertainty?”
Visibility is no longer earned by technical alignment alone, but by clarity, usefulness, and intent resolution. Content that helps users think better, decide faster, or understand deeper becomes inherently discoverable—because it aligns with how cognitive search systems evaluate value.
Final Thought
The future of search isn’t about being found.
It’s about being understood.
